 Cost-effective, Multilingual, Privacy-driven voice-enabled Services
Cost-effective, Multilingual, Privacy-driven voice-enabled Services
Voice-enabled, interactive devices are becoming more and more ubiquitous in the consumer market. Under the hood, these systems use Machine Learning (ML) to reach the best performance. This requires a large amount of speech and language data, especially, when more than one language is supported by the system. These data are usually stored in the cloud, and they often require manual analysis in preparation for the ML technology – something that gives an advantage to big non-European companies who can afford laborious preprocessing. Some users may also prefer these companies not to store their personal data in the first place.
The H2020 project COMPRISE defines a fully private-by-design methodology and tools that will reduce the cost and increase the inclusiveness of voice interaction technology through research advances on privacy-driven data transformations, personalized learning, automatic labeling, and integrated translation. The vision is to filter out privacy-threatening portions of the user data before storing them in the cloud.
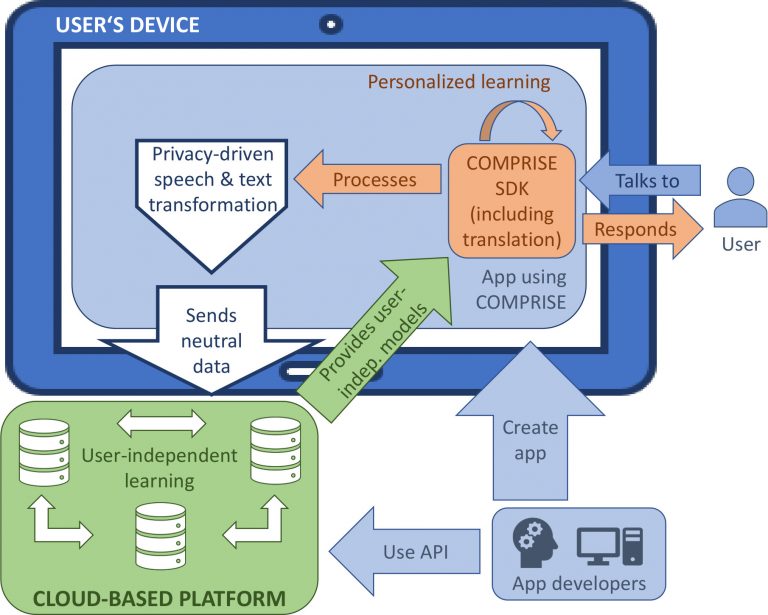
COMPRISE will provide an easy-to-use software development kit that interoperates with this cloud-based resource to enable businesses in the Digital Single Market to quickly develop multilingual voice-enabled services in many languages and allow all citizens to transparently access contents and services available in other languages by voice interaction in their own language. This will lead to cost savings for both technology providers and users.
Further information can be found on the project website.
Make sure to follow the project’s Twitter and LinkedIn accounts for the latest news and updates.